
Semantic future prediction is important for autonomous systems navigating dynamic environments. This paper introduces FUTURIST, a method for multimodal future semantic prediction that uses a unified and efficient visual sequence transformer architecture. Our approach incorporates a multimodal masked visual modeling objective and a novel masking mechanism designed for multimodal training. This allows the model to effectively integrate visible information from various modalities, improving prediction accuracy. Additionally, we propose a VAE-free hierarchical tokenization process, which reduces computational complexity, streamlines the training pipeline, and enables end-to-end training with high-resolution, multimodal inputs. We validate FUTURIST on the Cityscapes dataset, demonstrating state-of-the-art performance in future semantic segmentation for both short- and mid-term forecasting.
Our framework employs modality-specific embedders to map inputs into tokens. Then, these token embeddings are fused through token-wise concatenation to form the combined input embedding \(\mathrm{Z}\). Next, a masked transformer processes \(\mathrm{Z}\), capturing spatiotemporal dependencies between modalities, and outputs \(\mathrm{\tilde{Z}}\). Finally, modality-specific decoders produce future frame predictions for each modality based on \(\mathrm{\tilde{Z}}\), enabling efficient and accurate multimodal semantic future prediction within a unified architecture. Tokens are shown in 2D (not flattened) for visualization purposes.
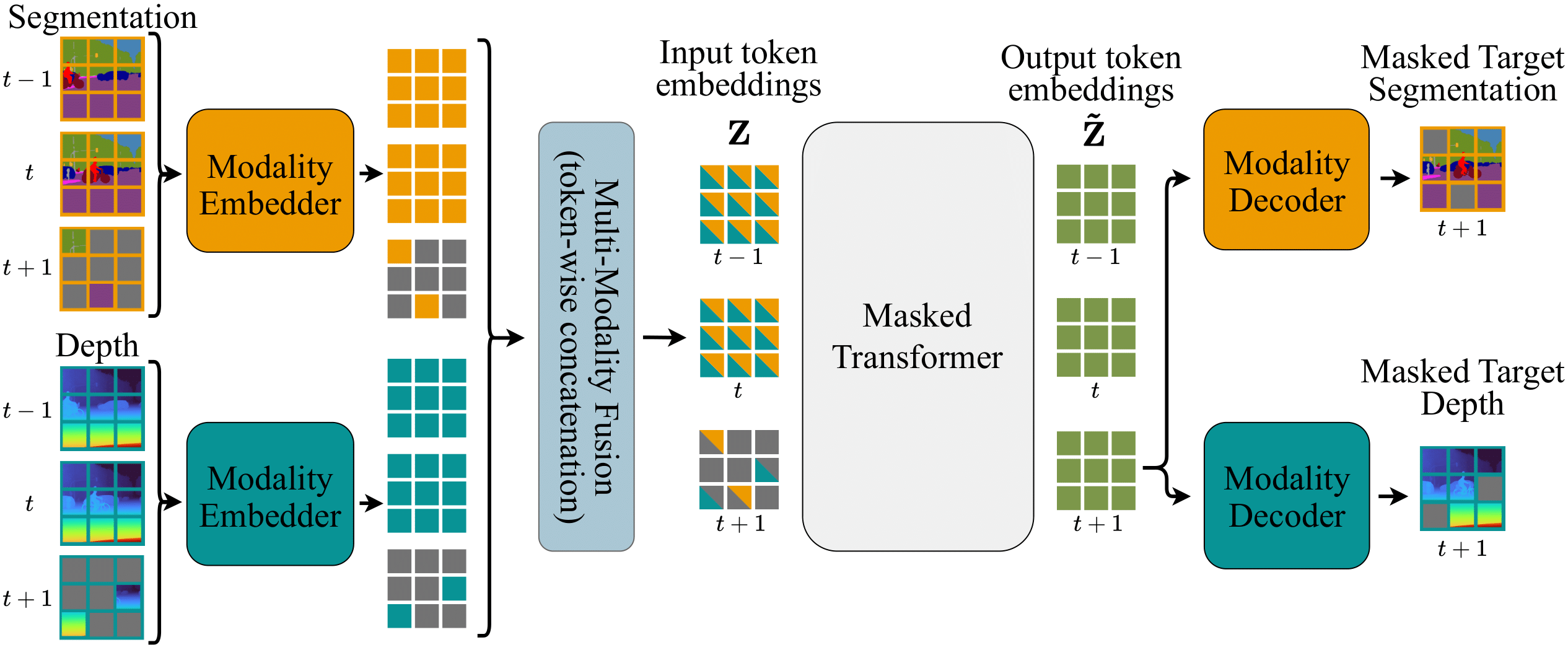
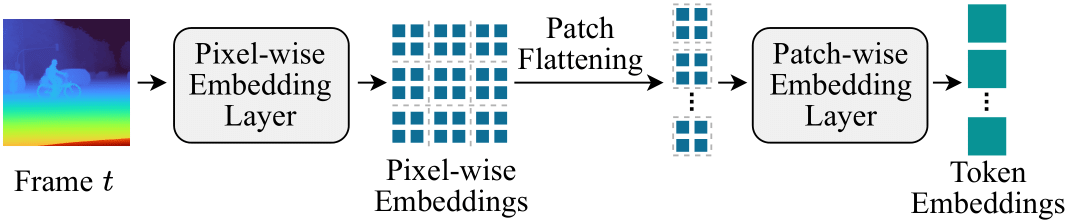
VAE-free Multimodal Embedder: Our framework employs a novel tokenization approach that eliminates the dependency on VAE-based tokenizers commonly used in video generation models. This lightweight, hierarchical two-stage embedding process enables efficient end-to-end training while maintaining computational efficiency for multimodal inputs.
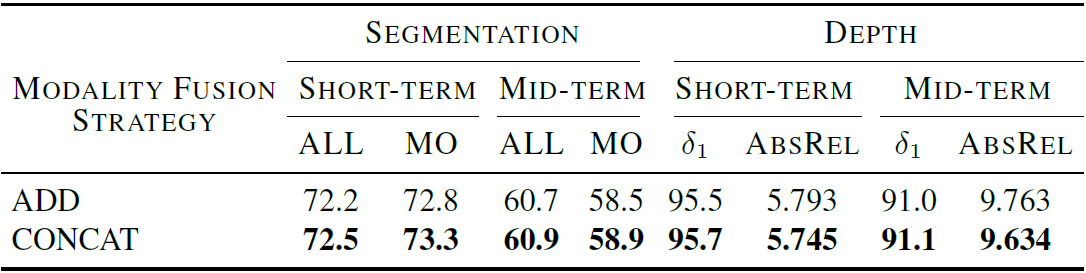
Cross Modal Fusion: Our approach integrates multiple semantic modalities by merging tokens across different modalities that share the same spatiotemporal location. We explored two fusion strategies: CONCAT (concatenating embeddings) and ADD (summing embeddings). As shown in the first table, CONCAT consistently outperforms ADD across all metrics, making it our default choice. The second table demonstrates that our multimodal fusion approach achieves superior performance when compared to separate tokens approach under the same compute budget.

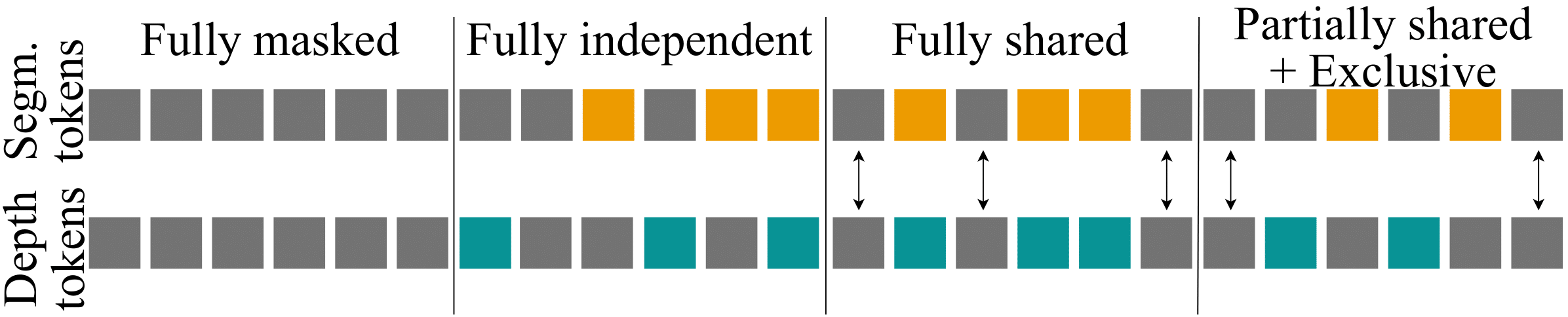
Multimodal Masking Strategy: We investigated several masking strategies to improve multimodal learning efficiency and accuracy. The Partially-shared and exclusive masking approach enforces learning cross-modal dependencies by selectively masking tokens across modalities, enabling the model to better exploit synergy between modalities.
Scaling Training Epochs: Longer training significantly improves our model's performance for both segmentation and depth prediction. As shown in the figure, mIoU and AbsRel metrics improve steadily with increased epochs for short-term and mid-term predictions.
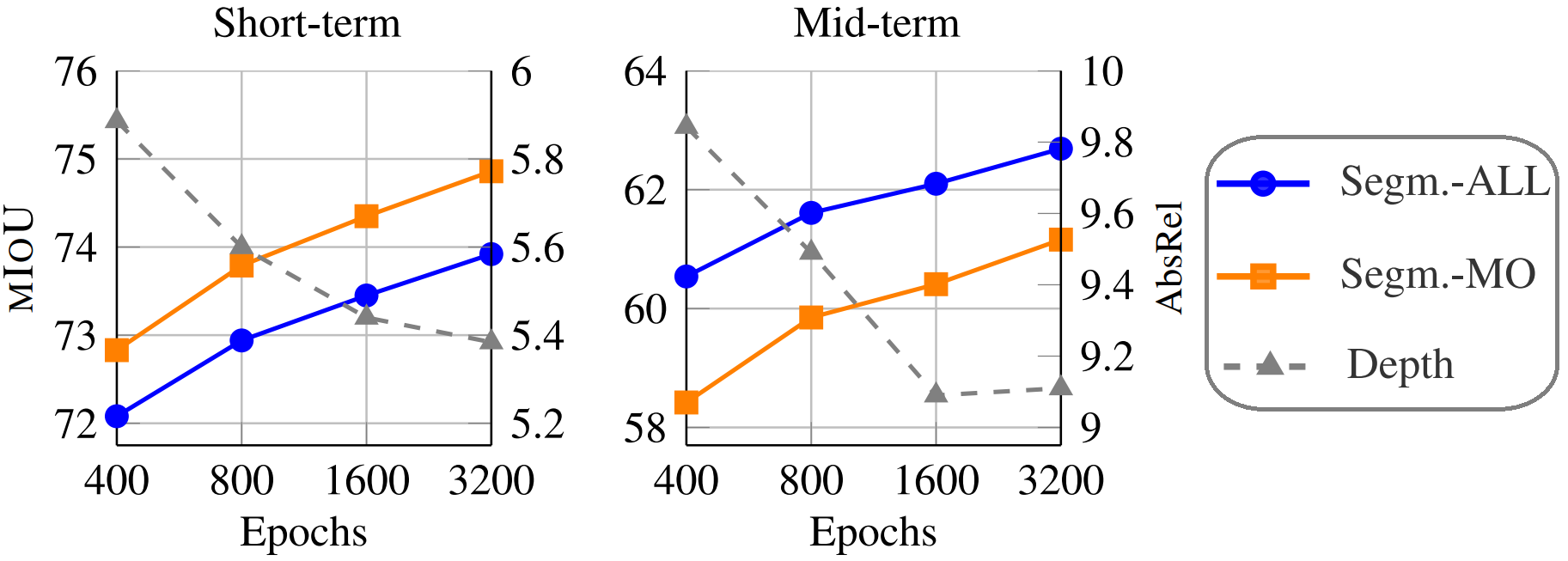
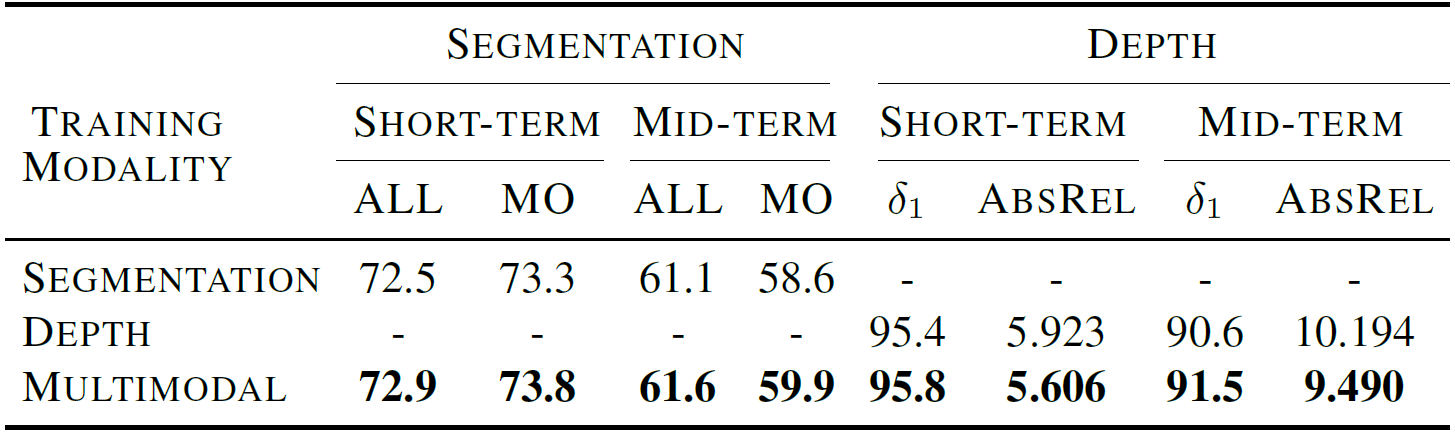
Synergistic Joint Prediction: Exploiting multimodal synergy boosts accuracy beyond single-modality models. The table demonstrates that the combined segmentation and depth training outperforms separate models, highlighting the strength of our unified approach.
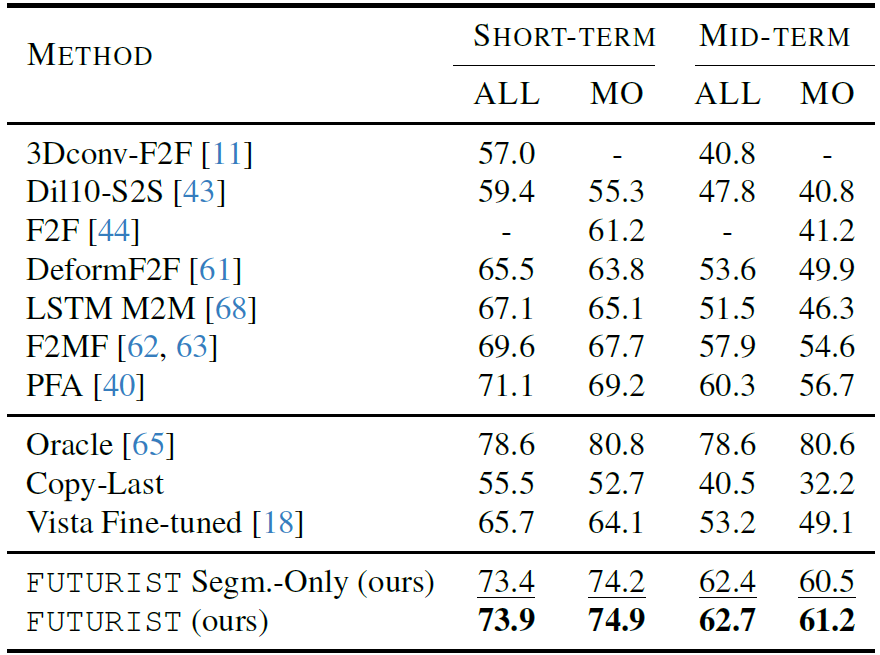
We achieve state-of-the-art results for future semantic prediction. Here we compare against prior methods, with Oracle representing the upper bound performance. We also include the weak Copy-Last baseline and introduce Vista as stronger baseline.




@InProceedings{Karypidis_2025_CVPR,
author = {Karypidis, Efstathios and Kakogeorgiou, Ioannis and Gidaris, Spyros and Komodakis, Nikos},
title = {Advancing Semantic Future Prediction through Multimodal Visual Sequence Transformers},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2025},
pages = {3793-3803}
}